TL;DR
This analysis looks at top U.S. computer science programs from the perspective of faculty origin: where current professors received their highest degrees.
The main finding is that the “Big Four” in CS: MIT, Stanford, CMU, and UC Berkeley, are not just strong in rankings. They also form the center of an elite faculty-hiring network. Top CS departments hire many faculty members who were trained at these four schools, especially MIT and Stanford, which appear to have the broadest national reach across the dataset.
At the same time, the data also shows that schools such as UIUC, University of Washington (UW Seattle), Georgia Tech, UT Austin, University of Michigan, Cornell, and Princeton have strong academic influence. They may not always be grouped with the Big Four, but their PhD graduates clearly appear in the faculty pipelines of top CS programs.
So the overall takeaway is simple:
CS prestige is not just a ranking list. It is a network.
The Big Four sit at the center of that network, but other research powerhouses also play an important role in shaping the academic world of computer science.
It has been a while since I posted my last blog about CS rankings on April 10, 2026. While I have been enjoying the happiness of becoming an upcoming freshman at UC Berkeley as a Computer Science major, I have also been digging further into the top CS programs in the United States.
This time, instead of looking only at rankings, I wanted to look at top CS programs from another perspective: faculty origin.
In other words, where did the faculty at top CS programs receive their highest degrees? If a department hires many professors trained at certain universities, that may tell us something about how top programs view each other academically.
Hopefully, this analysis can help young researchers and students think about their academic road ahead, especially if they are considering academia instead of industry.
When people talk about top computer science programs, they usually talk about rankings.
U.S. News has one list. CSRankings has another. Niche, College Factual, and other websites all create their own versions of what “top CS” means. In my earlier post, I wrote about how these rankings often measure different things: reputation, research output, student experience, selectivity, or some combination of all of them.
But there is another way to look at CS prestige that I find especially interesting:
Where did the faculty at top CS programs get their degrees?
Instead of asking how schools rank themselves or how external ranking systems evaluate them, we can ask a different question:
When elite CS departments hire professors, which doctoral programs do they seem to trust the most?
This gives us another lens into how top CS programs view each other.
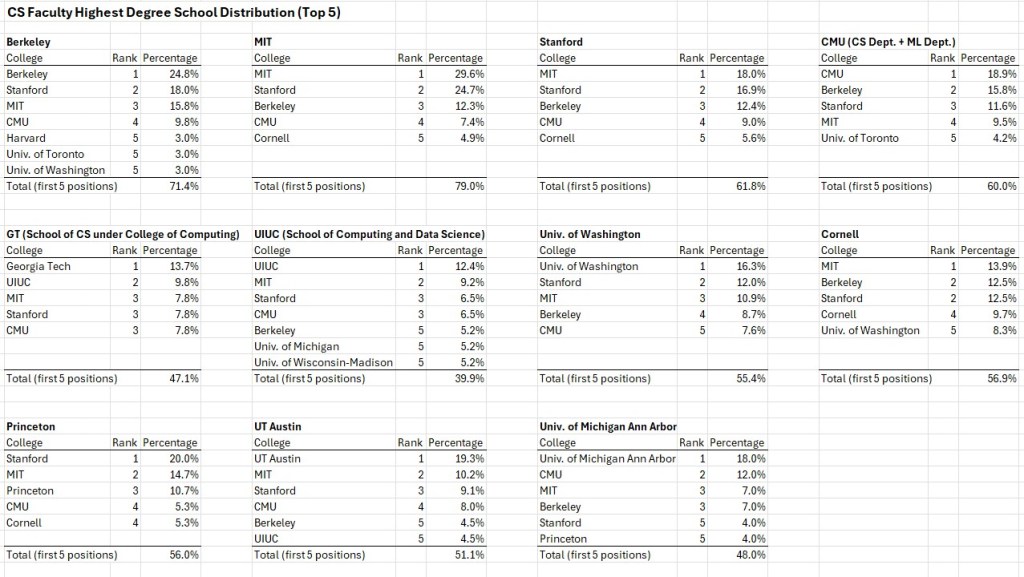
For this analysis, I looked at a summary of faculty educational backgrounds from several top U.S. computer science departments. The data was extracted from each school’s official website as of May 29, 2026. For CMU, I only counted faculty from the Computer Science Department and the Machine Learning Department within the School of Computer Science. Since the data comes from public faculty profiles, it is not a complete record of every hiring decision. It does not show the full applicant pool, interview process, postdoc experience, or research fit behind each hire.
Still, it reveals something meaningful: the academic “pipeline” behind top CS faculty.
And the pattern is clear.
The Big Four Are Real
In computer science, people often refer to the “Big Four”: MIT, Stanford, Carnegie Mellon, and UC Berkeley.
These four schools are widely recognized as Tier 1 CS programs. Of course, exact rankings vary from year to year. In some rankings, CMU, MIT, and Stanford may be tied at the top, while Berkeley may be slightly lower. In other rankings, Berkeley may appear higher depending on the methodology. But the specific order is less important than the larger pattern.
These four schools consistently form the core of elite CS.
The faculty-degree data supports this idea strongly. Across the top CS departments in the dataset, MIT, Stanford, CMU, and Berkeley appear again and again as major sources of faculty training.
This is not just a rankings story. It is a hiring-network story.
Top CS departments are not only ranked highly by outsiders. They also seem to recognize each other as the strongest sources of future faculty.
A Prestige Loop Among Tier 1 Programs
The most striking trend is that Tier 1 schools tend to hire from each other.
MIT’s faculty origins are heavily concentrated in MIT, Stanford, Berkeley, and CMU. Berkeley’s are also heavily concentrated in Berkeley, Stanford, MIT, and CMU. Stanford and CMU show the same general pattern.
This creates what I would call a prestige loop.
The top programs produce PhD graduates. Other top programs hire them as faculty. Those faculty then train the next generation of PhD students, who may later become professors at other elite departments.
This cycle reinforces the academic status of these schools.
Among the schools in the dataset, the approximate share of faculty whose highest degree came from MIT, Stanford, CMU, or Berkeley was especially high at the Big Four themselves:
| Target CS Program | Approximate Big Four Share |
| MIT | 74.1% |
| UC Berkeley | 68.4% |
| Stanford | 56.2% |
| Carnegie Mellon | 55.8% |
This suggests that the Big Four are not just strong individually. They form a tightly connected ecosystem.
MIT and Berkeley show especially high Big Four concentration. Stanford and CMU are still strongly connected to the Big Four network, but their faculty origins appear slightly more distributed.
MIT and Stanford Have the Broadest Hiring Prestige
Another pattern is that MIT and Stanford appear to have the most universal prestige across the dataset.
MIT and Stanford show up in the top faculty-origin lists for every target school in the summary. CMU appears in nearly all of them, while Berkeley also appears very frequently.
This does not mean MIT and Stanford are “better” than Berkeley or CMU in every area. That would be too simplistic. CS is too broad for one ranking to capture everything. Different schools have different strengths in artificial intelligence, theory, systems, human-computer interaction, programming languages, robotics, and many other fields.
But from this faculty-origin perspective, MIT and Stanford seem to have the broadest national reach.
A PhD from MIT or Stanford appears to travel extremely well across top CS departments. CMU and Berkeley also have enormous prestige, but MIT and Stanford seem slightly more universally represented in this dataset.
The Second Layer of Elite CS Is Also Very Strong
The Big Four dominate the network, but they are not the whole story.
Schools like UIUC, University of Washington (UW Seattle), Cornell, Princeton, Georgia Tech, UT Austin, and University of Michigan also appear as important faculty pipelines.
This matters because it complicates the simple prestige narrative.
If we only looked at a traditional reputation ranking, we might focus too much on the very top few schools. But faculty hiring shows that many other research-intensive CS departments also have real academic influence.
For example, UIUC appears as a major source in several departments. Georgia Tech and University of Washington (UW Seattle) also show strong self-pipeline effects. Michigan, UT Austin, Cornell, and Princeton each show up as important contributors in the broader network.
This connects to one of the main points from my earlier CS rankings post: different ranking systems capture different aspects of strength.
U.S. News is heavily reputation-driven. CSRankings focuses more on faculty research output. Niche and other undergraduate-focused rankings may emphasize student experience, outcomes, or campus life.
Faculty hiring gives us another dimension: peer recognition through doctoral training.
A school’s faculty-degree footprint tells us how much other departments seem to value its PhD graduates.
Self-Pipeline Is Another Important Signal
Another interesting pattern is self-hiring or self-pipeline strength.
Many top CS programs have a significant number of faculty who received their highest degree from the same institution. MIT, Berkeley, CMU, Stanford, University of Washington (UW Seattle), UIUC, Michigan, Georgia Tech, UT Austin, Cornell, and Princeton all show this pattern to varying degrees.
MIT and Berkeley stand out the most.
| Target School | Approximate Self-Origin Share |
| MIT | 29.6% |
| UC Berkeley | 24.8% |
| UT Austin | 19.3% |
| CMU | 18.9% |
| University of Michigan | 18.0% |
| Stanford | 16.9% |
| University of Washington (UW Seattle) | 16.3% |
This does not necessarily mean these schools are directly hiring their own PhD students immediately after graduation. In many cases, a faculty member may earn a PhD from one school, work elsewhere, and later return.
Still, a high self-origin share suggests that a department strongly values its own doctoral training culture.
It also shows how elite academic communities can reproduce themselves over time.
What This Says About CS Prestige
To me, the main takeaway is that CS prestige is not just about a single ranking number.
A school’s reputation is shaped by multiple layers:
- Peer reputation
- Research output
- Faculty hiring networks
- Doctoral training strength
- Undergraduate experience
- Industry and graduate-school outcomes
The Big Four are powerful because they perform well across many of these dimensions. They are highly ranked, highly productive, and deeply embedded in the faculty hiring networks of other top programs.
But other schools also show major strength. UIUC, University of Washington (UW Seattle), Georgia Tech, UT Austin, Michigan, Cornell, and Princeton are not simply “below” the Big Four. They are major research institutions with their own hiring influence.
This is why I think CS rankings should be read carefully.
A ranking may say one school is #1 and another is #5, but the real academic world is more networked than linear. Prestige is not just a ladder. It is also a map.
My Overall Interpretation
The faculty-degree data shows that elite computer science hiring is strongly shaped by doctoral prestige networks.
MIT, Stanford, CMU, and UC Berkeley form the core of this network. Among them, MIT and Stanford appear to have the broadest representation across top departments, while CMU and Berkeley remain central members of the same Tier 1 ecosystem.
At the same time, the data also shows that research-intensive programs such as UIUC, Georgia Tech, University of Washington (UW Seattle), UT Austin, Michigan, Cornell, and Princeton have significant influence. These schools may not always be grouped with the Big Four in casual conversations, but their PhD graduates are clearly part of the elite CS faculty pipeline.
So the best conclusion is not simply that “the Big Four dominate,” even though they clearly do.
The more interesting conclusion is this:
Top CS faculty hiring reflects a prestige network, not just a ranking list.
The Big Four sit at the center of that network, but the surrounding research powerhouses also play an important role. Together, they reveal how top CS departments actually recognize, reproduce, and reinforce academic prestige.
For students who are thinking about an academic path, this matters. If someone wants to become a professor or researcher in computer science, the department where they receive doctoral training may shape not only their education, but also how they are viewed in the broader academic job market.
That does not mean only a few schools matter. Strong research can come from many places. But the faculty-origin data does show that academia has networks, and those networks are not random.
Understanding those networks can help students make more informed decisions about graduate school, research direction, and long-term academic goals.
Appendix
5,886 hits