Every year, a single word captures the moment when language and culture meet. Sometimes it comes from politics, sometimes from technology, but it always tells a story about how people think and communicate. As someone drawn to both words and code, I see each new “Word of the Year” as more than a headline. It’s data, meaning, and evolution all at once.
As I prepare to study Computational Linguistics in college, I have been paying attention not only to algorithms and corpora but also to the ways language changes around us. One of the most interesting reflections of that change is the annual “Word of the Year” chosen by Collins Dictionary. In this post, I’ll review the past ten years of Collins’ selections, explain how the 2025 Word of the Year was chosen (including the shortlist), and discuss why this matters for computational linguistics.
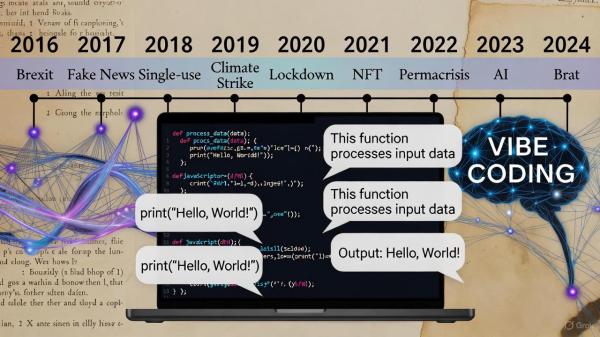
Past Ten Years of Collins Word of the Year
| Year | Word of the Year | Brief explanation |
| 2016 | Brexit | Captured the UK’s vote to leave the EU and its wide political, social, and linguistic effects. |
| 2017 | fake news | Reflected the rise of misinformation and debates about truth in media. |
| 2018 | single-use | Highlighted environmental awareness and discussions about disposable culture. |
| 2019 | climate strike | Described global youth activism inspired by Greta Thunberg and climate movements. |
| 2020 | lockdown | Defined the year of the Covid-19 pandemic and its global restrictions. |
| 2021 | NFT | Stood for “non-fungible token” and represented the emergence of digital assets and blockchain culture. |
| 2022 | permacrisis | Described a long period of instability and uncertainty, fitting the global mood. |
| 2023 | AI | Represented artificial intelligence becoming central to everyday conversation. |
| 2024 | brat | Captured the confident, independent attitude popularized by youth culture and pop music. |
| 2025 | vibe coding | Described the blending of language and technology through conversational code creation. |
The 2025 Word of the Year: vibe coding
For 2025, Collins Dictionary selected vibe coding as its Word of the Year. The term refers to new software development practices that use natural language and artificial intelligence to create applications by describing what one wants rather than manually writing code. It describes a form of “coding by conversation” that bridges creativity and computation.
Source: Collins Dictionary Word of the Year 2025
How Collins Selects the Word of the Year
The Collins team monitors its extensive language database throughout the year. Using large-scale corpus analysis, they track words that rise sharply in frequency or reflect cultural, political, or technological change. The process includes:
- Lexicographic monitoring: Editors and linguists identify new or trending words across print, social media, and digital sources.
- Corpus analysis: Statistical tools measure frequency and context to see which words stand out.
- Editorial review: The final decision balances data and cultural relevance to choose a word that captures the spirit of the year.
Shortlist for 2025
In addition to vibe coding, this year’s shortlist includes aura farming, biohacking, broligarchy, clanker, coolcation, glaze, HENRY, micro-retirement, and taskmasking.
You can view the full list on the Collins website: https://www.collinsdictionary.com/us/woty
Why the Collins Word of the Year Matters for Computational Linguistics
As someone preparing to study Computational Linguistics, I find the Collins Word of the Year fascinating for several reasons:
- Language change in data
Each year’s word shows how new vocabulary enters real-world language use. Computational linguistics often studies these changes through corpora to model meaning over time. - Human-machine interaction
Vibe coding reflects a growing trend where natural language acts as an interface between humans and technology. It is an example of how linguistic principles are now shaping software design. - Semantic and cultural evolution
The meanings of words like “brat” or “AI” evolve quickly in digital contexts. For computational linguists, tracking these semantic shifts supports research in language modeling and word embeddings. - Lexicographic data as research input
Collins’ approach mirrors computational methods. Their frequency-based analysis can inspire how we model and predict linguistic trends using data science. - Pedagogical and research relevance
New words like vibe coding demonstrate how emerging technology changes both everyday communication and the future topics of linguistic research. They show where language innovation meets computation.
Reflection
When I first read that “vibe coding” had been chosen as the 2025 Word of the Year, I couldn’t help thinking about how it perfectly represents where computational linguistics is heading. Language is no longer just a subject of study; it is becoming a tool for creation. What used to be a set of rigid commands is turning into natural conversation.
The term also reminds me that words are living data points. Each new entry in a dictionary records a shift in how people think and communicate. For future computational linguists, observing how dictionaries evolve gives insight into how models and algorithms should adapt too.
It’s easy to see the Word of the Year as a piece of pop culture, but it’s really a linguistic dataset in disguise. Every annual choice documents how society expresses what matters most at that moment, and that is what makes it so meaningful to study.
Sources and Links
— Andrew
5,279 hits