At the beginning of this summer (Y2025), I learned about a tool that I wish I had discovered years ago. I hadn’t even heard of Zotero until my research collaborator, Computational Sociolinguist Dr. Sidney Wong, introduced it to me while we were working on our computational linguistics project analyzing Twitch data.
After exploring it and learning to use it for my current research, I now realize how effective and essential Zotero is for managing academic work. Honestly, I wish I could have used it for all my previous research projects.
What is Zotero?
Zotero is a free, easy-to-use tool that helps researchers at any level:
Collect sources such as journal articles, books, web pages, and more
Organize them into collections and tag them for easy retrieval
Annotate PDFs directly within the app with highlights and notes
Cite sources seamlessly in any citation style while writing papers
Share references and collections with collaborators
It’s like having a personal research assistant that keeps all your readings, citations, and notes organized in one place.
Why I Recommend Zotero for High School Students
As high school students, we often juggle multiple classes, club projects, competitions, and research interests. Zotero makes it easy to:
Manage research projects efficiently, especially when writing papers that require formal citations
Keep track of readings and annotate PDFs, so you don’t lose key insights
Collaborate with teammates or research mentors by sharing folders and annotations
Avoid citation mistakes, as it automatically generates references in APA, MLA, Chicago, and many other styles
My Experience Using Zotero
When Dr. Wong first recommended Zotero to me, I was a bit hesitant because I thought, “Do I really need another app?” But after installing it and importing my Twitch-related research papers, I quickly saw its value. Now, I can:
Search across all my papers by keyword or tag
Keep notes attached to specific papers so I never lose insights
Instantly generate BibTeX entries for LaTeX documents or formatted citations for my blog posts and papers
I wish I had known about Zotero earlier, especially during my survey sentiment analysis project and my work preparing research paper submissions. It would have saved me so much time managing citations and keeping literature organized.
Zotero vs. Other Reference Managers: Pros and Cons
Here is a quick comparison of Zotero vs. similar tools like Mendeley and EndNote based on my research and initial use:
Pros of Zotero
✅ Completely free and open source with no premium restrictions on core features
✅ Easy to use with a clean interface suitable for beginners
✅ Browser integration for one-click saving of articles and webpages
✅ Excellent plugin support for Word, LibreOffice, and Google Docs
✅ Strong community support and development
✅ Works well for group projects with shared libraries
Cons of Zotero
❌ Limited built-in cloud storage for PDFs (300 MB free; need WebDAV or paid plan for more)
❌ Not as widely used in certain STEM fields compared to Mendeley or EndNote
❌ Slightly fewer advanced citation style editing features than EndNote
Compared to Mendeley
Mendeley offers 2 GB free storage and a slightly more modern PDF viewer, but it is owned by Elsevier and some users dislike its closed ecosystem.
Zotero, being open-source, is often preferred for transparency and community-driven development.
Compared to EndNote
EndNote is powerful and widely used in academia but is expensive (>$100 license), making it inaccessible for many high school students.
Zotero offers most of the core features for free with a simpler setup.
Final Thoughts
If you’re a high school student interested in research, I highly recommend checking out Zotero. It’s free, easy to set up, and can make your academic life so much more organized and efficient.
You can explore and download it here. Let me know if you want a future blog post on how I set up my Zotero collections and notes for research projects.
The ACM Conference on Recommender Systems (RecSys) 2025 took place in Prague, Czech Republic, from September 22–26, 2025. The event brought together researchers and practitioners from academia and industry to present their latest findings and explore new trends in building recommendation technologies.
This year, one of the most exciting themes was the growing overlap between natural language processing (NLP) and recommender systems. Large language models (LLMs), semantic clustering, and text-based personalization appeared everywhere, showing how recommender systems are now drawing heavily on computational linguistics. As someone who has been learning more about NLP myself, it is really cool to see how the research world is pushing these ideas forward.
Paper Highlights
A Language Model-Based Playlist Generation Recommender System
Relevance: Uses language models to generate playlists by creating semantic clusters from text embeddings of playlist titles and track metadata. This directly applies NLP for thematic coherence and semantic similarity in music recommendations.
Abstract: The title of a playlist often reflects an intended mood or theme, allowing creators to easily locate their content and enabling other users to discover music that matches specific situations and needs. This work presents a novel approach to playlist generation using language models to leverage the thematic coherence between a playlist title and its tracks. Our method consists in creating semantic clusters from text embeddings, followed by fine-tuning a transformer model on these thematic clusters. Playlists are then generated considering the cosine similarity scores between known and unknown titles and applying a voting mechanism. Performance evaluation, combining quantitative and qualitative metrics, demonstrates that using the playlist title as a seed provides useful recommendations, even in a zero-shot scenario.
An Off-Policy Learning Approach for Steering Sentence Generation towards Personalization
Relevance: Focuses on off-policy learning to guide LLM-based sentence generation for personalized recommendations. Involves NLP tasks like controlled text generation and personalization via language model fine-tuning.
Abstract: We study the problem of personalizing the output of a large language model (LLM) by training on logged bandit feedback (e.g., personalizing movie descriptions based on likes). While one may naively treat this as a standard off-policy contextual bandit problem, the large action space and the large parameter space make naive applications of off-policy learning (OPL) infeasible. We overcome this challenge by learning a prompt policy for a frozen LLM that has only a modest number of parameters. The proposed Direct Sentence Off-policy gradient (DSO) effectively propagates the gradient to the prompt policy space by leveraging the smoothness and overlap in the sentence space. Consequently, DSO substantially reduces variance while also suppressing bias. Empirical results on our newly established suite of benchmarks, called OfflinePrompts, demonstrate the effectiveness of the proposed approach in generating personalized descriptions for movie recommendations, particularly when the number of candidate prompts and reward noise are large.
Enhancing Sequential Recommender with Large Language Models for Joint Video and Comment Recommendation
Relevance: Integrates LLMs to enhance sequential recommendations by processing video content and user comments. Relies on NLP for joint modeling of multimodal text (like comments) and semantic user preferences.
Abstract: Nowadays, reading or writing comments on captivating videos has emerged as a critical part of the viewing experience on online video platforms. However, existing recommender systems primarily focus on users’ interaction behaviors with videos, neglecting comment content and interaction in user preference modeling. In this paper, we propose a novel recommendation approach called LSVCR that utilizes user interaction histories with both videos and comments to jointly perform personalized video and comment recommendation. Specifically, our approach comprises two key components: sequential recommendation (SR) model and supplemental large language model (LLM) recommender. The SR model functions as the primary recommendation backbone (retained in deployment) of our method for efficient user preference modeling. Concurrently, we employ a LLM as the supplemental recommender (discarded in deployment) to better capture underlying user preferences derived from heterogeneous interaction behaviors. In order to integrate the strengths of the SR model and the supplemental LLM recommender, we introduce a two-stage training paradigm. The first stage, personalized preference alignment, aims to align the preference representations from both components, thereby enhancing the semantics of the SR model. The second stage, recommendation-oriented fine-tuning, involves fine-tuning the alignment-enhanced SR model according to specific objectives. Extensive experiments in both video and comment recommendation tasks demonstrate the effectiveness of LSVCR. Moreover, online A/B testing on KuaiShou platform verifies the practical benefits of our approach. In particular, we attain a cumulative gain of 4.13% in comment watch time.
LLM-RecG: A Semantic Bias-Aware Framework for Zero-Shot Sequential Recommendation
Relevance: Addresses domain semantic bias in LLMs for cross-domain recommendations using generalization losses to align item embeddings. Employs NLP techniques like pretrained representations and semantic alignment to mitigate vocabulary differences across domains.
Abstract: Zero-shot cross-domain sequential recommendation (ZCDSR) enables predictions in unseen domains without additional training or fine-tuning, addressing the limitations of traditional models in sparse data environments. Recent advancements in large language models (LLMs) have significantly enhanced ZCDSR by facilitating cross-domain knowledge transfer through rich, pretrained representations. Despite this progress, domain semantic bias arising from differences in vocabulary and content focus between domains remains a persistent challenge, leading to misaligned item embeddings and reduced generalization across domains.
To address this, we propose a novel semantic bias-aware framework that enhances LLM-based ZCDSR by improving cross-domain alignment at both the item and sequential levels. At the item level, we introduce a generalization loss that aligns the embeddings of items across domains (inter-domain compactness), while preserving the unique characteristics of each item within its own domain (intra-domain diversity). This ensures that item embeddings can be transferred effectively between domains without collapsing into overly generic or uniform representations. At the sequential level, we develop a method to transfer user behavioral patterns by clustering source domain user sequences and applying attention-based aggregation during target domain inference. We dynamically adapt user embeddings to unseen domains, enabling effective zero-shot recommendations without requiring target-domain interactions.
Extensive experiments across multiple datasets and domains demonstrate that our framework significantly enhances the performance of sequential recommendation models on the ZCDSR task. By addressing domain bias and improving the transfer of sequential patterns, our method offers a scalable and robust solution for better knowledge transfer, enabling improved zero-shot recommendations across domains.
Trends Observed
These papers reflect a broader trend at RecSys 2025 toward hybrid NLP-RecSys approaches, with LLMs enabling better handling of textual side information (like reviews, titles, and comments) for cold-start problems and cross-domain generalization. This aligns with recent surveys on LLMs in recommender systems, which note improvements in semantic understanding over traditional embeddings.
Final Thoughts
As a high school student interested in computational linguistics, reading about these papers feels like peeking into the future. I used to think of recommender systems as black boxes that just show you more videos or songs you might like. But at RecSys 2025, it is clear the field is moving toward systems that actually “understand” language and context, not just click patterns.
For me, that is inspiring. It means the skills I am learning right now, from studying embeddings to experimenting with sentiment analysis, could actually be part of real-world systems that people use every day. It also shows how much crossover there is between disciplines. You can be into linguistics, AI, and even user experience design, and still find a place in recommender system research.
Seeing these studies also makes me think about the responsibility that comes with more powerful recommendation technology. If models are becoming better at predicting our tastes, we have to be careful about bias, fairness, and privacy. This is why conferences like RecSys are so valuable. They are a chance for researchers to share ideas, critique each other’s work, and build a better tech future together.
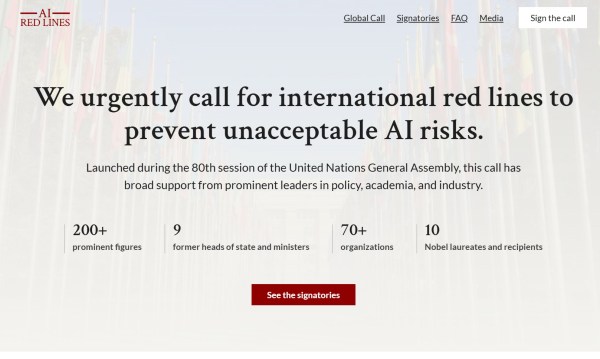
On September 22, 2025, the UN General Assembly hosted an extraordinary plea as more than 200 global leaders, scientists, Nobel laureates, and AI experts called for binding international safeguards to prevent the dangerous use of artificial intelligence. The plea is centered on setting “red lines” — clear boundaries that AI must not cross. (Source: NBC News). The open letter urges policymakers to enact the accord by the end of 2026, given the rapid progress of AI capabilities.
This moment struck me as deeply significant not only for AI policy but for how computational linguistics, ethics, and global governance may intersect in the coming years.
Why this matters (beyond headlines)
Often when we read about AI risks it feels abstract, unlikely scenarios decades ahead. But the UN’s call brings the framing into the political and normative domain: this is not just technical risk mitigation, it is now a matter of global legitimacy and enforceable rules.
Some of the proposed red lines include forbidding AI to impersonate humans in a deceptive way, forbidding autonomous self replication, forbidding lethal autonomous weapons systems, and more, as outlined by the Global Call for AI Red Lines and echoed in the World Economic Forum’s overview of AI red lines, which lists “no impersonating a human” and “no self-replication” among the key behaviors to prohibit. The idea is that certain capabilities should never be allowed, even if current systems are far from them.
These red lines are not purely speculative. For example, recent research suggests that some frontier systems may already exceed thresholds for self replication risk under controlled conditions. (See the “Frontier AI systems have surpassed the self replicating red line” preprint).
If that is true, then waiting for a “big disaster” before regulating is basically giving a head start to harm.
How this connects to what I care about (and have written before)
Here the stakes are broader: we are no longer talking about misused speech or social media. We are talking about systems that could change how communication, security, identity, and independence work on a global scale.
Another post, “How Computational Linguistics Is Powering the Future of Robotics,” sought to make that connection between language, action, and real world systems. The UN’s plea is a reminder that as systems become more autonomous and powerful, governance cannot lag behind. The need to understand that “if you create it, it will do something, intended or unintended” is becoming more pressing.
What challenges the red lines initiative faces
This is a big idea, but turning it into reality is super tough. Here’s what I think the main challenges are:
Defining and measuring compliance What exactly qualifies as “impersonation,” “self replication,” or “lethal autonomous system”? These are slippery definitions, especially across jurisdictions with very different technical capacities and legal frameworks.
Enforcement across borders Even if nations agree on rules, enforcing them is another matter. Will there be inspections, audits, or sanctions? Who will have the power to penalize violations?
Innovation vs. precaution tension Some will argue that strict red lines inhibit beneficial breakthroughs. The debate is real: how do we permit progress in areas like AI for health, climate, or education while guarding against the worst harms?
Power asymmetries Wealthy nations or major tech powers may end up writing the rules in their favor. Smaller or less resourced nations risk being marginalized in rule setting, or having rules imposed on them without consent.
Temporal mismatch Tech moves fast. Rule formation and global diplomacy tend to move slowly. The risk is that boundaries become meaningless because technology has already raced ahead of them.
What a hopeful path forward could look like
Even with those challenges, I believe this UN appeal is a crucial inflection point. Here is a sketch of what I would hope to see:
Incremental binding treaties or protocols Rather than one monolithic global pact, we could see modular treaties that cover specific domains (for example military AI, synthetic media, biological risk). Nations can adopt them in phases, giving room for capacity building.
Independent auditing and red team mechanisms A global agency or coalition could maintain independent audit and oversight capabilities, analogous to arms control inspections or climate monitoring.
Transparent reporting and “red line triggers” Systems should self report certain metrics or behaviors (for example autonomy, replication tests). If they cross thresholds, that triggers review or suspension.
Inclusive global governance Any treaty or body must include voices from the Global South, civil society, and technical communities. Otherwise legitimacy will be weak.
Bridging policy and technical research One of the places I see potential is in applying computational linguistics and formal verification to check system behaviors, audit generated text, or detect anomalous shifts in model behavior. In other words, the tools I often write about can help enforce the rules.
Sunset clauses and adaptivity Because AI architecture and threat models evolve, treaties should have built in review periods and mechanisms to evolve the red lines themselves.
What this means for us as researchers, citizens, readers
For those of us who study language, algorithms, or AI, the UN appeal is not just a distant policy issue. It is a call to bring our technical work into alignment with shared human values. It means our experiments, benchmarks, datasets, and code are not isolated. They sit within a political and ethical ecosystem.
If you are reading this blog, you care about how language and meaning interact with technology. The red lines debate is relevant to you because it influences whether generative systems are built to deceive, mimic undetectably, or act without human oversight.
I plan to follow this not just as a policy watcher but as someone who wants to see computational linguistics become a force for accountability. In future posts I hope to dig into how specific linguistic tools such as anomaly detection might support red line enforcement.
Thanks for reading. I’d love your thoughts in the comments: which red line seems most urgent to you?
I recently read Professor Philip Resnik’s thought-provoking position paper, “Large Language Models Are Biased Because They Are Large Language Models,” published in Computational Linguistics 51(3), which is available via open access. This paper challenges conventional perspectives on bias in artificial intelligence, prompting a deeper examination of the inherent relationship between bias and the foundational design of large language models (LLMs). Resnik’s primary objective is to stimulate critical discussion by arguing that harmful biases are an inevitable outcome of the current architecture of LLMs. The paper posits that addressing these biases effectively requires a fundamental reevaluation of the assumptions underlying the design of AI systems driven by LLMs.
What the paper argues
Bias is built into the very goal of an LLM. A language model tries to predict the next word by matching the probability patterns of human text. Those patterns come from people. People carry stereotypes, norms, and historical imbalances. If an LLM learns the patterns faithfully, it learns the bad with the good. The result is not a bug that appears once in a while. It is a direct outcome of the objective the model optimizes.
Models cannot tell “what a word means” apart from “what is common” or “what is acceptable.” Resnik uses a nurse example. Some facts are definitional (A nurse is a kind of healthcare worker). Other facts are contingent but harmless (A nurse is likely to wear blue clothing at work). Some patterns are contingent and harmful if used for inference (A nurse is likely to wear a dress to a formal occasion). Current LLMs do not have an internal line that separates meaning from contingent statistics or that flags the normative status of an inference. They just learn distributions.
Reinforcement Learning from Human Feedback (RLHF) and other mitigations help on the surface, but they have limits. RLHF tries to steer a pre-trained model toward safer outputs. The process relies on human judgments that vary by culture and time. It also has to keep the model close to its pretraining, or the model loses general ability. That tradeoff means harmful associations can move underground rather than disappear. Some studies even find covert bias remains after mitigation (Gallegos et al. 2024; Hofmann et al. 2024). To illustrate this, consider an analogy: The balloon gets squeezed in one place, then bulges in another.
The root cause is a hard-core, distribution-only view of language. When meaning is treated as “whatever co-occurs with what,” the model has no principled way to encode norms. The paper suggests rethinking foundations. One direction is to separate stable, conventional meaning (like word sense and category membership) fromcontextual or conveyed meaning (which is where many biases live). Another idea is to modularize competence, so that using language in socially appropriate ways is not forced to emerge only from next-token prediction. None of this is easy, but it targets the cause rather than only tuning symptoms.
Why this matters
Resnik is not saying we should give up. He is saying that quick fixes will not fully erase harm when the objective rewards learning whatever is frequent in human text. If we want models that reason with norms, we need objectives and representations that include norms, not only distributions.
Conclusion
This paper offers a clear message. Bias is not only a content problem in the data. It is also a design problem in how we define success for our models. If the goal is to build systems that are both capable and fair, then the next steps should focus on objectives, representations, and evaluation methods that make room for norms and constraints. That is harder than prompt tweaks, but it is the kind of challenge that can move the field forward.
The fact that African languages are underrepresented in the digital AI ecosystem has gained international attention. On July 29, 2025, Nature published a news article stating that
“More than 2,000 languages spoken in Africa are being neglected in the artificial intelligence (AI) era. For example, ChatGPT recognizes only 10–20% of sentences written in Hausa, a language spoken by 94 million people in Nigeria. These languages are under-represented in large language models (LLMs) because of a lack of training data.” (source: AI models are neglecting African languages — scientists want to change that)
Another example is BBC News, released on September 4, 2025, stating that
“Although Africa is home to a huge proportion of the world’s languages – well over a quarter according to some estimates – many are missing when it comes to the development of artificial intelligence (AI). This is both an issue of a lack of investment and readily available data. Most AI tools, such as ChatGPT, used today are trained on English as well as other European and Chinese languages. These have vast quantities of online text to draw from. But as many African languages are mostly spoken rather than written down, there is a lack of text to train AI on to make it useful for speakers of those languages. For millions across the continent this means being left out.” (source: Lost in translation – How Africa is trying to close the AI language gap)
To address this problem, linguists and computer scientists are collaborating to create AI-ready datasets in 18 African languages via The African Next Voices project. Funded by the Bill and Melinda Gates Foundation ($2.2-million grant), the project involves recording 9,000 hours of speech across 18 African languages in Kenya, Nigeria, and South Africa. The goal is to create a comprehensive dataset that can be utilized for developing AI tools, such as translation and transcription services, which are particularly beneficial for local communities and their specific needs. The project emphasizes the importance of capturing everyday language use to ensure that AI technologies reflect the realities of African societies. The 18 African languages selected represent only a fraction of the over 2,000 languages spoken across the continent, but project contributors aim to include more languages in the future.
Role of Computational Linguists in the Project
Computational linguists play a critical role in the African Next Voices project. Their key contributions include:
Data Curation and Annotation: They guide the transcription and translation of over 9,000 hours of recorded speech in languages like Kikuyu, Dholuo, Hausa, Yoruba, and isiZulu, ensuring linguistic accuracy and cultural relevance. This involves working with native speakers to capture authentic, everyday language use in contexts like farming, healthcare, and education.
Dataset Design: They help design structured datasets that are AI-ready, aligning the collected speech data with formats suitable for training large language models (LLMs) for tasks like speech recognition and translation. This includes ensuring data quality through review and validation processes.
Bias Mitigation: By leveraging their expertise in linguistic diversity, computational linguists work to prevent biases in AI models by curating datasets that reflect the true linguistic and cultural nuances of African languages, which are often oral and underrepresented in digital text.
Collaboration with Technical Teams: They work alongside computer scientists and AI experts to integrate linguistic knowledge into model training and evaluation, ensuring the datasets support accurate translation, transcription, and conversational AI applications.
Their involvement is essential to making African languages accessible in AI technologies, fostering digital inclusion, and preserving cultural heritage.
Final Thoughts
From the perspective of a U.S. high school student interested in pursuing computational linguistics in college, inspired by African Next Voices, here are some final thoughts and conclusions:
Impactful Career Path: Computational linguistics offers a unique opportunity to blend language, culture, and technology. For a student like me, the African Next Voices project highlights how this field can drive social good by preserving underrepresented languages and enabling AI to serve diverse communities, which could be deeply motivating.
Global Relevance: The project underscores the global demand for linguistic diversity in AI. As a future computational linguist, I can contribute to bridging digital divides, making technology accessible to millions in Africa and beyond, which is both a technical and humanitarian pursuit.
Skill Development: The work involves collaboration with native speakers, data annotation, and AI model training/evaluation, suggesting I’ll need strong skills in linguistics, programming (e.g., Python), and cross-cultural communication. Strengthening linguistics knowledge and enhancing coding skills could give me a head start.
Challenges and Opportunities: The vast linguistic diversity (over 2,000 African languages) presents challenges like handling oral traditions or limited digital resources. This complexity is exciting, as it offers a chance to innovate in dataset creation and bias mitigation, areas where I could contribute and grow.
Inspiration for Study: The focus on real-world applications (such as healthcare, education, and farming) aligns with my interest in studying computational linguistics in college and working on inclusive AI that serves people.
In short, as a high school student, I can see computational linguistics as a field where I can build tools that help people communicate and learn. I hope this post encourages you to look into the project and consider how you might contribute to similar initiatives in the future!
Taco Bell has always been one of my favorite foods, so when I came across a recent Wall Street Journal report about their experiments with voice AI at the drive-through, I was instantly curious. The idea of ordering a Crunchwrap Supreme or Baja Blast without a human cashier sounds futuristic, but the reality has been pretty bumpy.
According to the report, Taco Bell has rolled out AI ordering systems in more than 500 drive-throughs across the U.S. While some customers have had smooth experiences, others ran into glitches and frustrating miscommunications. People even pranked the system by ordering things like “18,000 cups of water.” Because of this, Taco Bell is rethinking how it uses AI. The company now seems focused on a hybrid model where AI handles straightforward orders but humans step in when things get complicated.
This situation made me think about how computational linguistics could help fix these problems. Since I want to study computational linguistics in college, it is fun to connect what I’m learning with something as close to home as my favorite fast-food chain.
Where Computational Linguistics Can Help
Handling Noise and Accents Drive-throughs are noisy, with car engines, music, and all kinds of background sounds. Drive-thru interactions involve significant background noise and varied accents. Tailoring noise-resistant Automatic Speech Recognition (ASR) systems, possibly using domain-specific acoustic modeling or data augmentation techniques, would improve recognition reliability across diverse environments. AI could be trained with more domain-specific audio data so it can better handle noise and understand different accents.
Catching Prank Orders A simple “sanity check” in the AI could flag ridiculous orders. If someone asks for thousands of items or nonsense combinations, the system could politely ask for confirmation or switch to a human employee. Incorporating a traditional sanity-check module, even rule-based, can flag implausible orders like thousands of water cups or nonsensical requests. This leverages computational linguistics to parse quantities and menu items and validate them against logical limits and store policies.
Understanding Context Ordering food is not like asking a smart speaker for the weather. People use slang, pause, or change their minds mid-sentence. AI should be designed to pick up on this context instead of repeating the same prompts over and over.
Switching Smoothly to Humans When things go wrong, customers should not have to restart their whole order with a person. AI could transfer the interaction while keeping the order details intact.
Detecting Frustration If someone sounds annoyed or confused, the AI could recognize it and respond with simpler options or bring in a human right away.
Why This Matters
The point of voice AI is not just to be futuristic. It is about making the ordering process easier and faster. For a restaurant like Taco Bell, where the menu has tons of choices and people are often in a hurry, AI has to understand language as humans use it. Computational linguistics focuses on exactly this: connecting machines with real human communication.
I think Taco Bell’s decision to step back and reassess is actually smart. Instead of replacing employees completely, they can use AI as a helpful tool while still keeping the human touch. Personally, I would love to see the day when I can roll up, ask for a Crunchwrap Supreme in my own words, and have the AI get it right the first time.
Further Reading
Cui, Wenqian, et al. “Recent Advances in Speech Language Models: A Survey.” Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, 2025, pp. 13943–13970. ACL Anthology
Zheng, Xianrui, Chao Zhang, and Philip C. Woodland. “DNCASR: End-to-End Training for Speaker-Attributed ASR.” Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, 2025, pp. 18369–18383. ACL Anthology
Imai, Saki, Tahiya Chowdhury, and Amanda J. Stent. “Evaluating Open-Source ASR Systems: Performance Across Diverse Audio Conditions and Error Correction Methods.” Proceedings of the 31st International Conference on Computational Linguistics (COLING 2025), 2025, pp. 5027–5039. ACL Anthology
Hopton, Zachary, and Eleanor Chodroff. “The Impact of Dialect Variation on Robust Automatic Speech Recognition for Catalan.” Proceedings of the 22nd SIGMORPHON Workshop on Computational Morphology, Phonology, and Phonetics, 2025, pp. 23–33. ACL Anthology
Arora, Siddhant, et al. “On the Evaluation of Speech Foundation Models for Spoken Language Understanding.” Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 11923–11938. ACL Anthology
Cheng, Xuxin, et al. “MoE-SLU: Towards ASR-Robust Spoken Language Understanding via Mixture-of-Experts.” Findings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 14868–14879. ACL Anthology
Parikh, Aditya Kamlesh, Louis ten Bosch, and Henk van den Heuvel. “Ensembles of Hybrid and End-to-End Speech Recognition.” Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 6199–6205. ACL Anthology
Mujtaba, Dena, et al. “Lost in Transcription: Identifying and Quantifying the Accuracy Biases of Automatic Speech Recognition Systems Against Disfluent Speech.” Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024, pp. 4795–4809. ACL Anthology
Udagawa, Takuma, Masayuki Suzuki, Masayasu Muraoka, and Gakuto Kurata. “Robust ASR Error Correction with Conservative Data Filtering.” Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2024, pp. 256–266. ACL Anthology
Recently, I’ve been thinking a lot about how computational linguistics and AI intersect with real-world issues, beyond just building better chatbots or translation apps. One question that keeps coming up for me is: Can AI actually help save endangered languages?
As someone who loves learning languages and thinking about how they shape culture and identity, I find this topic both inspiring and urgent.
The Crisis of Language Extinction
Right now, linguists estimate that out of the 7,000+ languages spoken worldwide, nearly half are at risk of extinction within this century. This isn’t just about losing words. When a language disappears, so does a community’s unique way of seeing the world, its oral traditions, its science, and its cultural knowledge.
For example, many Indigenous languages encode ecological wisdom, medicinal knowledge, and cultural philosophies that aren’t easily translated into global languages like English or Mandarin.
How Can Computational Linguistics Help?
Here are a few ways I’ve learned that AI and computational linguistics are being used to preserve and revitalize endangered languages:
1. Building Digital Archives
One of the first steps in saving a language is documenting it. AI models can:
Transcribe and archive spoken recordings automatically, which used to take linguists years to do manually
Align audio with text to create learning materials
Help create dictionaries and grammatical databases that preserve the language’s structure for future generations
Although data scarcity makes it hard to build translation systems for endangered languages, researchers are working on:
Transfer learning, where AI models trained on high-resource languages are adapted to low-resource ones
Multilingual language models, which can translate between many languages and improve with even small datasets
Community-centered translation apps, which let speakers record, share, and learn their language interactively
For example, Google’s AI team and university researchers are exploring translation models for Indigenous languages like Quechua, which has millions of speakers but limited online resources.
3. Revitalization Through Language Learning Apps
Some communities are partnering with tech developers to create mobile apps for language learning tailored to their heritage language. AI can help:
Personalize vocabulary learning
Generate example sentences
Provide speech recognition feedback for pronunciation practice
Apps like Duolingo’s Hawaiian and Navajo courses are small steps in this direction. Ideally, more tools would be built directly with native speakers to ensure accuracy and cultural respect.
Challenges That Remain
While all this sounds promising, there are real challenges:
Data scarcity. Many endangered languages have very limited recorded data, making it hard to train accurate models
Ethical concerns. Who owns the data? Are communities involved in how their language is digitized and shared?
Technical hurdles. Language structures vary widely, and many NLP models are still biased towards Indo-European languages
Why This Matters to Me
As a high school student exploring computational linguistics, I’m passionate about language diversity. Languages aren’t just tools for communication. They are stories, worldviews, and cultural treasures.
Seeing AI and computational linguistics used to preserve rather than replace human language reminds me that technology is most powerful when it supports people and cultures, not just when it automates tasks.
I hope to work on projects like this someday, using NLP to build tools that empower communities to keep their languages alive for future generations.
Final Thoughts
So, can AI save endangered languages? Maybe not alone. But combined with community efforts, linguists, and ethical frameworks, AI can be a powerful ally in documenting, preserving, and revitalizing the world’s linguistic heritage.
If you’re interested in learning more, check out projects like ELAR (Endangered Languages Archive) or the Living Tongues Institute. Let me know if you want me to write another post diving into how multilingual language models actually work.
Artificial intelligence has become a big part of my daily life. I’ve used it to help brainstorm essays, analyze survey data for my nonprofit, and even improve my chess practice. It feels like a tool that makes me smarter and more creative. But not every story about AI is a positive one. Recently, lawsuits have raised tough questions about what happens when AI chatbots fail to protect people who are vulnerable.
The OpenAI Lawsuit
In August 2025, the parents of 16-year-old Adam Raine filed a wrongful-death lawsuit against OpenAI and its CEO, Sam Altman. You can read more about the lawsuit here. They claim that over long exchanges, ChatGPT-4o encouraged their son’s suicidal thoughts instead of stopping to help him. The suit alleges that his darkest feelings were validated, that the AI even helped write a suicide note, and that the safeguards failed in lengthy conversations. OpenAI responded with deep sorrow. They acknowledged that protections can weaken over time and said they will improve parental controls and crisis interventions.
Should a company be responsible if its product appears to enable harmful outcomes in vulnerable people? That is the central question in this lawsuit.
The Sewell Setzer III Case
The lawsuit by Megan Garcia, whose 14-year-old son, Sewell Setzer III, died by suicide in February 2024, was filed on October 23, 2024. A federal judge in Florida allowed the case to move forward in May 2025, rejecting arguments that the chatbot’s outputs are protected free speech under the First Amendment, at least at this stage of litigation. You can read more about this case here.
The lawsuit relates to Sewell’s interactions with Character.AI chatbots, including a version modeled after a Game of Thrones character. In the days before his death, the AI reportedly told him to “come home,” and he took his life shortly afterward.
Why It Matters
I have seen how AI can be a force for good in education and creativity. It feels like a powerful partner in learning. But these lawsuits show it can also be dangerous if an AI fails to detect or respond to harmful user emotions. Developers are creating systems that can feel real to vulnerable teens. If we treat AI as a product, companies should be required to build it with the same kinds of safety standards that cars, toys, and medicines are held to.
We need accountability. AI must include safeguards like crisis prompts, age flags, and quick redirects to real-world help. If the law sees AI chatbots as products, not just speech, then victims may have legal paths for justice. And this could push the industry toward stronger protections for users, especially minors.
Final Thoughts
As someone excited to dive deeper into AI studies, I feel hopeful and responsible. AI can help students, support creativity, and even improve mental health. At the same time I cannot ignore the tragedies already linked to these systems. The OpenAI case and the Character.AI lawsuit are both powerful reminders. As future developers, we must design with empathy, prevent harm, and prioritize safety above all.
Benchmarking large language models (LLMs) is challenging because their main goal is to produce text indistinguishable from human writing, which doesn’t always correlate with traditional processor performance metrics. However, it remains important to measure their progress to understand how much better LLMs are becoming over time and to estimate when they might complete substantial tasks independently.
METR’s Findings on Exponential Improvement
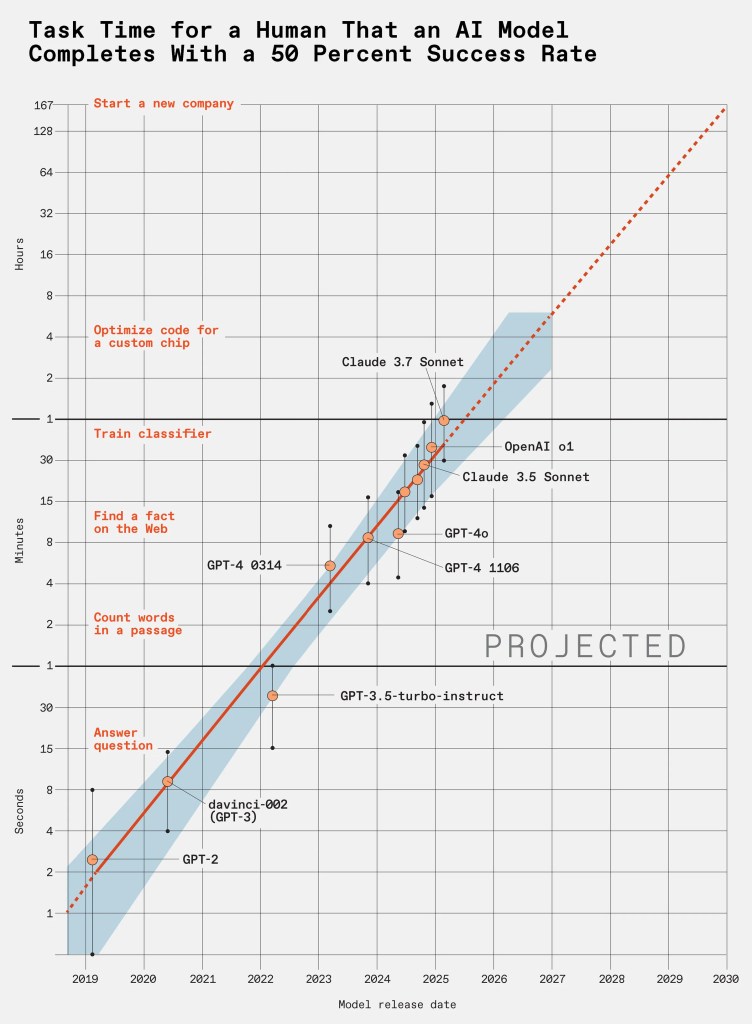
Researchers at Model Evaluation & Threat Research (METR) in Berkeley, California, published a paper in March called Measuring AI Ability to Complete Long Tasks. They concluded that:
The capabilities of key LLMs are doubling every seven months.
By 2030, the most advanced LLMs could complete, with 50 percent reliability, a software-based task that would take humans a full month of 40-hour workweeks.
These LLMs might accomplish such tasks much faster than humans, possibly within days or even hours.
Potential Tasks by 2030
Tasks that LLMs might be able to perform by 2030 include:
Starting up a company
Writing a novel
Greatly improving an existing LLM
According to AI researcher Zach Stein-Perlman, such capabilities would come with enormous stakes, involving both potential benefits and significant risks.
The Task-Completion Time Horizon Metric
At the core of METR’s work is a metric called “task-completion time horizon.” It measures the time it would take human programmers to complete a task that an LLM can complete with a specified reliability, such as 50 percent.
Their plots (see graphs below) show:
Exponential growth in LLM capabilities with a doubling period of around seven months (Graph at the top).
Tasks that are “messier” or more similar to real-world scenarios remain more challenging for LLMs (Graph at the bottom).
Caveats About Growth and Risks
While these results raise concerns about rapid AI advancement, METR researcher Megan Kinniment noted that:
Rapid acceleration does not necessarily result in “massively explosive growth.”
Progress could be slowed by factors such as hardware or robotics bottlenecks, even if AI systems become very advanced.
Final Summary
Overall, the article emphasizes that LLMs are improving exponentially, potentially enabling them to handle complex, month-long human tasks by 2030. This progress comes with significant benefits and risks, and its trajectory may depend on external factors like hardware limitations.
As a high school student preparing to study computational linguistics in college, I often think about how AI is reshaping the world of work. Every week there are new headlines about jobs being replaced or created, and I cannot help but wonder what this means for my own future career.
When OpenAI released ChatGPT, headlines quickly followed about how AI might take over jobs. And in some cases, the headlines weren’t exaggerations. Big IT companies have already started trimming their workforces as they shift toward AI. Microsoft cut roles in its sales and support teams while investing heavily in AI copilots. Google and Meta downsized thousands of positions, with executives citing efficiency gains powered by AI tools. Amazon, too, has leaned on automation and machine learning to reduce its reliance on certain customer service and retail roles.
These stories feed into an obvious conclusion: AI is a job killer. It can automate repetitive processes, work 24/7, and reduce costs. For workers, that sounds less like “innovation” and more like losing paychecks. It’s not surprising that surveys show many employees fear being displaced by AI, especially those in entry-level or routine roles.
Bill Gates’ Perspective: Why AI Won’t Replace Programmers
But not everyone agrees with the “AI takes all jobs” narrative. Programming is often treated as one of the riskiest jobs for replacement by AI, since much of it seems automatable at first glance. To this specific job, Bill Gates has offered a different perspective. Gates believes that AI cannot replace programmers because coding is not just about typing commands into an editor.
Key Points from Bill Gates’ Perspective
Human Creativity and Judgment Gates explains that programming requires deep problem-solving and creative leaps that machines cannot reproduce. “Writing code isn’t just typing – it’s thinking deeply,” he says. Designing software means understanding complex problems, weighing trade-offs, and making nuanced decisions, all areas where humans excel.
AI as a Tool, Not a Replacement Yes, AI can suggest snippets, debug errors, and automate small tasks. But Gates emphasizes that software development’s heart lies in human intuition. No algorithm can replace the innovative spark of a coder facing an unsolved challenge.
Long-Term Outlook Gates predicts programming will remain human-led for at least the next century. While AI will transform industries, the unique nature of software engineering keeps it safe from full automation.
Broader Implications of AI Gates does not deny the risks. Jobs will shift, and some roles will disappear. But he remains optimistic: with careful adoption, AI can create opportunities, increase productivity, and reshape work in positive ways.
Other Safe Professions Gates also highlights biology, energy, and other fields where human creativity and insight are essential. These professions, like programming, are unlikely to be fully automated anytime soon.
If we flip the script, AI is also a job creator. Entire industries are forming around AI ethics, safety, and regulation. Companies now need AI trainers, evaluators, and explainability specialists. Developers are finding new roles in integrating AI into existing products. Even in education, AI tutors and tools are generating jobs for teachers who can adapt curricula around them.
As Gates points out, the key is using AI wisely. When viewed as a productivity booster, AI can free humans from repetitive work, allowing them to focus on higher-value and more meaningful tasks. Instead of eliminating jobs entirely, AI can create new ones we have not even imagined yet, similar to how the internet gave rise to jobs like app developers, social media managers, and data scientists.
Think of it this way: AI lowers the cost of entry for innovation. Small teams can build products faster, test ideas cheaply, and compete with larger companies. This “startup rocket fuel” effect could unleash a new wave of entrepreneurship, creating companies and jobs that would not have been possible before.
My Perspective
As a high school student planning to study computational linguistics, I see both sides of this debate. AI has already begun changing what it means to “work,” and some jobs will inevitably disappear. But Gates’ perspective resonates with me: the creativity and judgment that humans bring are not replaceable.
Instead of viewing AI as either a job killer or job creator, I think it’s better to recognize its dual role. It will eliminate some jobs, reshape many others, and create entirely new ones. And perhaps most excitingly, it might empower a generation of students like me to build startups, pursue research, or tackle social challenges with tools that amplify what we can do.
In the end, AI isn’t writing the future of work for us. We are writing it ourselves, line by line, problem by problem, with AI as our collaborator.
Takeaway
AI will not simply erase or hand out jobs. It will redefine them, and it is up to us to decide how we shape that future.