When you type a question into a search engine like “Who wrote Hamlet?” it does more than match keywords. It connects the dots between “Shakespeare” and “Hamlet,” identifying the relationship between a person and their work. This process of finding and labelling relationships in text is called relation extraction (RE). It powers everything from knowledge graphs to fact-checking systems.
In the past, relation extraction systems were built with hand-crafted rules or required thousands of annotated examples to train. Now, large language models (LLMs) such as GPT, T5, and LLaMA are making it possible to do relation extraction with far less data and more flexibility. In this post, I want to explore what relation extraction is, how LLMs are transforming it, and why this matters for anyone interested in the future of language technology.
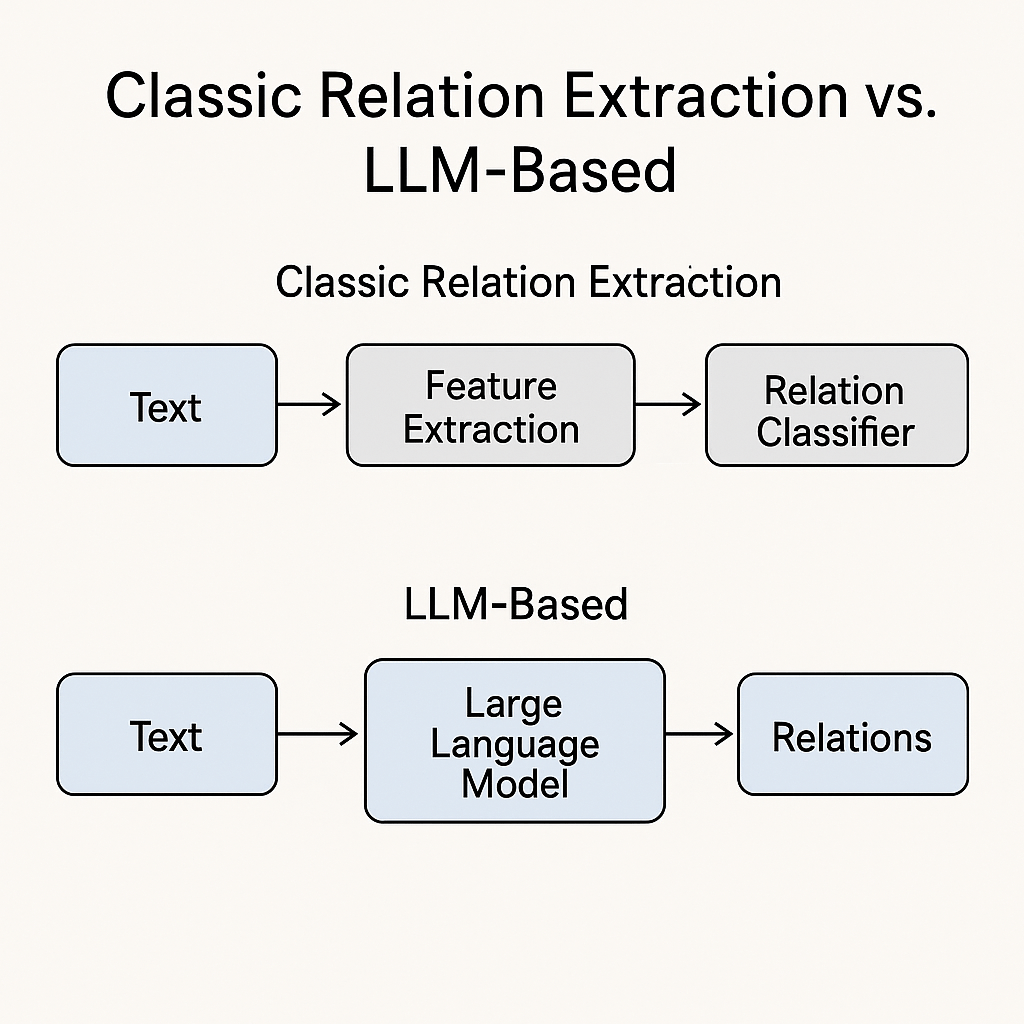
The Old Way Versus the New Way
Relation extraction used to rely heavily on feature engineering. Researchers would first hand-craft linguistic or statistical features from the text, such as part-of-speech tags, dependency parses, named entity types, and the words appearing between two entities. They often built lexical patterns like “X, the capital of Y” or “X, founded by Y” to capture specific relationships. They also extracted syntactic paths (for example, the shortest path between two entities in a dependency tree) or used windowed word embeddings around the entities to encode local context. These features were then fed into classifiers like Support Vector Machines, logistic regression models, or decision trees to decide which relationship best described the entity pair. Later, neural networks like BERT and RoBERTa replaced much of this manual feature design by learning their own representations directly from text, but they still needed large, labeled datasets to achieve good performance.
Today, LLMs can often handle relation extraction with just a prompt. Instead of training a model from scratch, you can ask an LLM directly: “Identify the relationship between ‘Einstein’ and ‘the theory of relativity.’” With the right instructions, the model can output the relation (“Einstein proposed the theory of relativity”) even if it has never seen that exact pair in training.
See the diagram showing “classic relation extraction pipeline” versus “LLM-based pipeline” below.
How LLMs Tackle Relation Extraction
LLMs have been trained on massive amounts of text, which gives them a broad sense of how entities and relationships co-occur. This makes them powerful at zero-shot and few-shot learning. In other words, you do not need to show them hundreds of examples of a relation type before they can identify it.
For example, a simple prompt could be:
Prompt:“Read the sentence: ‘Marie Curie discovered radium.’ What is the relationship between the entities?”
Model Output from ChatGPT-5 and Grok-4:
[ChatGPT-5] In the sentence “Marie Curie discovered radium”, the relationship between the entities is:
- Marie Curie (the subject / agent) performed the action.
- radium (the object / theme) is what was discovered.
This is a “discoverer–discovery” relationship (also called “person–invention/discovery” or “agent–object” in relation extraction). In other words, Marie Curie is the discoverer and radium is the thing discovered.
[Grok-4] In the sentence “Marie Curie discovered radium,” the relationship between the entities “Marie Curie” and “radium” is that of discoverer and discovered. Marie Curie, a scientist, is the person who identified or found the chemical element radium.
This ability to generalize makes LLMs more versatile, especially for relations in domains where labeled data is scarce, like medicine or law. However, it also introduces risks. LLMs may hallucinate relationships that are not actually in the text or mislabel subtle ones, so careful evaluation is still necessary.
Recent Research Highlights
A major paper, A Survey on Cutting-Edge Relation Extraction Techniques Based on Language Models (Diaz-Garcia & López, 2024), reviews 137 recent ACL papers (2020-2023) that use language models for relation extraction. It shows that BERT-based methods still lead many benchmarks while models like T5 are rising in few-shot and unseen-relation settings.
Other papers from ACL 2024 and 2025 explore how well LLMs handle unseen relation types, cross-domain relation extraction, and low-resource settings. These studies show steady improvements but also highlight open questions about factuality, bias, and consistency.
Why This Matters Beyond Academia
Relation extraction sits at the core of knowledge-driven applications. Building or updating a knowledge graph for a company’s internal documents, mapping patient histories in healthcare, or connecting laws to court cases in legal tech all depend on accurately identifying relationships between entities.
LLMs make it possible to automate these tasks more quickly. Instead of spending months labeling data, organizations can draft knowledge structures with an LLM, then have humans verify or refine the results. This speeds up research and decision-making while expanding access to insights that would otherwise stay hidden in text.
Challenges and Open Questions
While LLMs are powerful, they are not flawless. They may infer relationships that are plausible but incorrect, especially if the prompt is ambiguous. Evaluating relation extraction at scale is also difficult, because many relations are context-specific or only partially expressed. Bias in training data can also skew the relationships a model “sees” as likely or normal.
Researchers are now working on ways to add uncertainty estimates, retrieval-augmented methods (i.e., combining information retrieval with generative models to improve response accuracy and relevance), and better benchmarks to test how well models extract relations across different domains and languages.
My Take as a High Schooler Working in NLP
As someone who has built a survey analysis platform and published research papers about sentiment classification, I find relation extraction exciting because it can connect scattered pieces of information into a bigger picture. Specifically, for projects like my nonprofit Student Echo, a future system could automatically link student concerns to policy areas or resources.
At the same time, I am cautious. Seeing how easily LLMs generate answers reminds me that relationships in text are often subtle. Automating them risks oversimplifying complex realities. Still, the idea that a model can find and organize connections that would take a person hours to spot is inspiring and worth exploring.
Conclusion
Relation extraction is moving from hand-built rules and large labeled datasets to flexible, generalist large language models. This shift is making it easier to build knowledge graphs, extract facts, and understand text at scale. But it also raises new questions about reliability, fairness, and evaluation.
If you want to dig deeper, check out A Survey on Cutting-Edge Relation Extraction Techniques Based on Language Models (arXiv link) or browse ACL 2024–2025 papers on relation extraction. Watching how this field evolves over the next few years will be exciting, and I plan to keep following it for future blog posts.
— Andrew
5,286 hits